如果你用的是MacBook M1 Max,有着不错的64GB综合内存,且想在本地运行强大的开源大模型,用于日常搜索问答、代码生成,那么Mistral-7B-Instruct + DeepSeek-Coder-6.7B是相当理想的组合!本文将手把手教你,如何开始简单且享受开源大模型的快感体验!
一、选择合适的模型
根据你的需求(代码生成+搜索问答),下面是最适合M1 Max运行的模型列表:
| 模型名称 | 参数规模 | 特点 |
|---|---|---|
| Mistral-7B-Instruct | 7B | 指令跟随性高,答题精准、简洁 |
| DeepSeek-Coder-6.7B | 6.7B | 最新代码生成大模型,支持中英文代码) |
大模型就选这两个,比起72B这种过大模型,不会压力,运行流畅,并且效果优秀。
二、清晰流程一览图
参考下面这张流程图: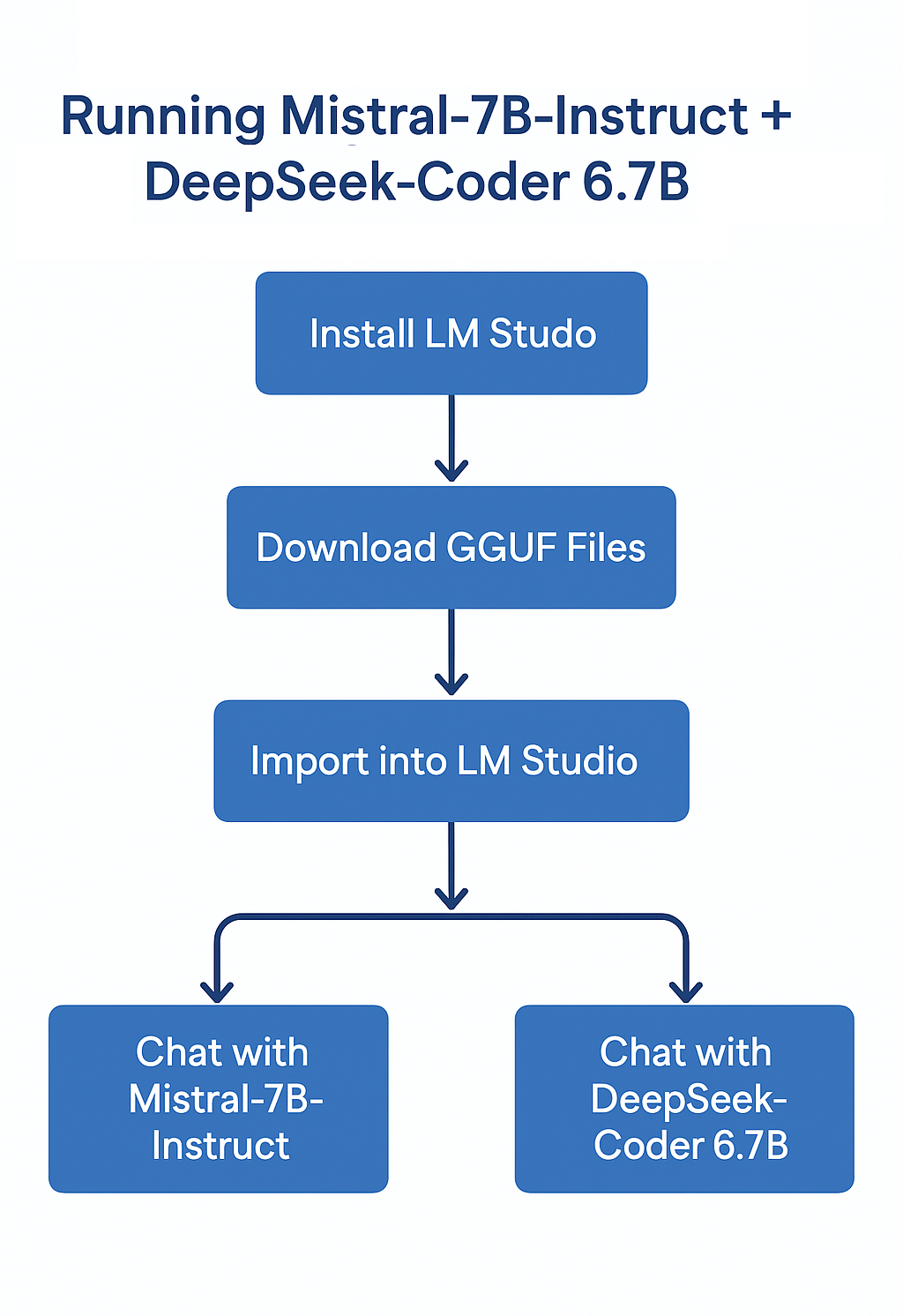
三、详细操作步骤
1.安装 LM Studio
- 访问:https://lmstudio.ai/
- 下载macOS版,直接安装
- 开启后看到第一行 “Metal Backend Activated” 就说明已经启用M1 Max硬件加速
2.下载合适的模型(GGUF格式)
选择 Q4_K_M 量化版,性能和内存使用不错。
3.将模型导入到 LM Studio
- 打开LM Studio → 选择”Local Models” → 点”Import Model”
- 选择下载的
.gguf文件 - 导入成功后,直接点”Chat” 就可以使用了
4.建议配置设置
- Context length:4096 tokens 或更多
- Batch size:设置成16,或使用自动
- CPU offload:如果太70可以开启
四、各自的最佳使用场景
| 场景 | 最佳模型 |
|---|---|
| 代码生成 | DeepSeek-Coder-6.7B |
| 搜索问答 | Mistral-7B-Instruct |
| 中文问答、小规模搜索 | Qwen-7B-Chat (Backup) |
如果你要写Python、C++以及写接口文档,直接用DeepSeek-Coder-6.7B答题,效果出奇场!
日常搜索,例如查详详节信息,概括新闻,直接用Mistral-7B-Instruct,较为简洁。
简单总结
一口气总结:安装 LM Studio → 下载 GGUF → 导入模型 → 开始聊天、写代码!



